3.2öĄ(sh©┤)ō■(j©┤)Ęų╝ēĘĮĘ©Ą─ąį─▄
▒Š╬─═©▀^į┌Tri-RightŽĄĮy(t©»ng)╔Ž▀Mąątrace“īäėĄ─īŹ“ׯ¼įuār┴╦AutoMigĄ─ąį─▄Ż¼īŹ“×ųą╩╣ė├Ą─╬─╝■įLå¢trace╩Ūė╔╝ėų▌┤¾īW▓«┐╦└¹ĘųąŻĄ─RoseliĄ╚╚╦▓╔╝»Ą─research traceĪŻ
×ķ┴╦äō(chu©żng)Į©Ęų╝ē┤µā”ŽĄĮy(t©»ng)ųąšµīŹĄ─öĄ(sh©┤)ō■(j©┤)Ęų▓╝ĀŅæB(t©żi)Ż¼į┌▓źĘ┼įLå¢traceĄ─═¼ĢrŻ¼─ŻöMųžč▌┴╦30╠ņĄ─╬─╝■▀węŲąą×ķŻ¼▓╗╣▄traceųąĄ─įLå¢ķgĖ¶Ż¼ėøõø╬─╝■▀węŲĀŅæB(t©żi)Č°▓╗▀Mąąšµš²Ą─öĄ(sh©┤)ō■(j©┤)▓┘ū„Ż¼Ą├ĄĮūŅĮKĄ─ŽĄĮy(t©»ng)ĀŅæB(t©żi)Ż¼░³└©╬─╝■┤¾ąĪĪó╬─╝■╬╗ų├ĪóLRUĻĀ┴ąą┼Žó║═įLå¢ŪķørĮy(t©»ng)ėŗĄ╚Ż¼╚╗║¾Ż¼į┌Tri-RightŽĄĮy(t©»ng)ųąīó─ŻöMĄ├ĄĮĄ─ŽĄĮy(t©»ng)ĀŅæB(t©żi)╗ųÅ═▀^üĒŻ¼▀@śėŻ¼╝╚Ą├ĄĮ┴╦īŹ“×╦∙ąĶĄ─│§╩╝ĀŅæB(t©żi)Ż¼ėų▒▄├Ō┴╦šµīŹŽĄĮy(t©»ng)╔ŽķLŲ┌▓źĘ┼trace╦∙ąĶĄ─┤¾┴┐ĢrķgĪŻ
į┌Tri-RightŽĄĮy(t©»ng)╔Ž▓źĘ┼research traceųąĄ┌31╠ņŪ░12 hĄ─įLå¢ėøõøŻ¼Ė▀╦┘┤µā”įOéõ╚▌┴┐╚ĪųĄ×ķ1 GB.į¬öĄ(sh©┤)ō■(j©┤)Ę■äšŲ„▄ø╝■Ęųäe▓╔ė├LRUŻ¼GreedyDualSize║═AutoMig 3ĘNöĄ(sh©┤)ō■(j©┤)Ęų╝ē▓▀┬įŻ¼Ū░├µā╔ĘNöĄ(sh©┤)ō■(j©┤)Ęų╝ē▓▀┬įöĄ(sh©┤)ō■(j©┤)╔²╝ēįuārČ╝╩Ū▓╔ė├on-demandĘĮ╩ĮŻ¼ėąįL墊═╔²╝ē▀węŲŻ╗öĄ(sh©┤)ō■(j©┤)ĮĄ╝ēįuārĘųäe▓╔ė├LRU║═GreedyDualSize╦ŃĘ©▀Mąą╠µōQĪŻ
łD3Įo│÷┴╦╩╣ė├3ĘN▓╗═¼öĄ(sh©┤)ō■(j©┤)Ęų╝ē▓▀┬įŽ┬Ū░┼_I/OĄ─ŲĮŠ∙Ēææ¬ĢrķgĄ─ūā╗»ŪķørŻ¼ÖMū°ś╦×ķtraceōuĘ┼ĢrķgŻ¼ī”æ¬┐vū°ś╦▒Ē╩ŠÅ─OĄĮįōĢrķg³cĘČć·ā╚(n©©i)Ą─ŲĮŠ∙I/OĒææ¬ĢrķgŻ¼┐╔ęį┐┤│÷Ż¼į┌Äū║§╚½▓┐īŹ“×▀^│╠ųąŻ¼AutoMigĄ─ŲĮŠ∙I/OĒææ¬Ģrķg├„’@Ą═ė┌╩╣ė├Ųõ╦¹ā╔ĘN▓▀┬įĢrĄ─ŲĮŠ∙I/OĒææ¬ĢrķgŻ¼ĮY╣¹▒Ē├„Ż║┼cLRU║═GreedyDualSizeŽÓ▒╚Ż¼AutoMigĄ─ŲĮŠ∙I/OĒææ¬ĢrķgĘųäeŽ┬ĮĄ┴╦10. 11%║═39. 39%ĪŻ
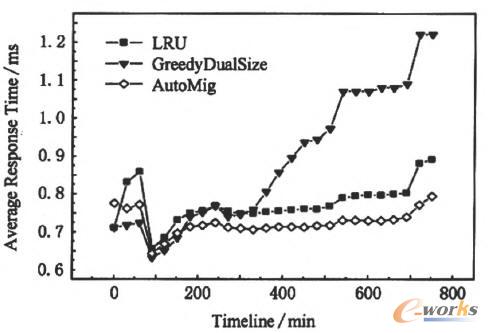
łD3 ▓╗═¼öĄ(sh©┤)ō■(j©┤)Ęų╝ē▓▀┬įŽ┬Ą─Ēææ¬Ģrķgī”▒╚
AutoMigĒææ¬ĢrķgĖ³Č╠Ą─įŁę“į┌ė┌AutoMig▀węŲĖ³╔┘Ą─öĄ(sh©┤)ō■(j©┤)┴┐Ż¼łD4ī”▒╚┴╦3ĘNöĄ(sh©┤)ō■(j©┤)Ęų╝ē▓▀┬įĄ─öĄ(sh©┤)ō■(j©┤)▀węŲ┐é┴┐Ż¼į┌╩╣ė├AutoMig▓▀┬įĢrŻ¼öĄ(sh©┤)ō■(j©┤)▀węŲ┴┐▒╚LRU║═GreedyDuaISizeĘųäe£p╔┘┴╦70. 71%║═90, 47%ĪŻ
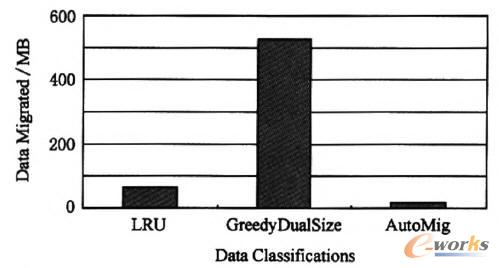
łD4 ▓╗═¼öĄ(sh©┤)ō■(j©┤)Ęų╝ē▓▀┬įŽ┬Ą─öĄ(sh©┤)ō■(j©┤)▀węŲ┴┐ī”▒╚
3.3 ĻP┬ō(li©ón)╬─╝■═┌Š“Ą─ą¦╣¹
▀@ę╗ĮMīŹ“×╩╣ė├Ą─╬─╝■įLå¢trace╩Ū▓«┐╦└¹Ą─instruction trace.░čķLĄ─įLå¢traceŪąĖŅ│╔ą“┴ąöĄ(sh©┤)ō■(j©┤)ÄņŻ¼╩╣ė├Ą─ŪąĖŅķLČ╚×ķ100-īŹ“×ųąŻ¼ūŅąĪų¦│ųČ╚║═ūŅąĪ┐╔ą┼Č╚Č╝╚Ī▓╗═¼Ą─ųĄĪŻ
AutoMig╩ūŽ╚ꬥ├ĄĮŅlĘ▒ķ]║Žą“┴ąŻ¼į┌Ą├ĄĮŅlĘ▒ķ]║Žą“┴ą║¾Ż¼ąĶę¬▀Mę╗▓Į╔·│╔¤o╚▀ėÓĄ─ÅŖĻP┬ō(li©ón)ęÄ(gu©®)ätŻ¼īŹ“×ųąŻ¼╬ęķTßśī”0. 3,0. 4,0.5╚²ĘN▓╗═¼Ą─ūŅąĪų¦│ųČ╚▀x╚ĪŅlĘ▒ķ]║Žą“┴ąŻ¼ūŅąĪ┐╔ą┼Č╚ķōųĄČ╝╚ĪųĄ×ķ85%Ż¼łD5Įo│÷┴╦AutoMig╔·│╔Ą─¤o╚▀ėÓĄ─ÅŖĻP┬ō(li©ón)ęÄ(gu©®)ätéĆöĄ(sh©┤)Ż¼▓óĘųäeĮo│÷┴╦“1-ęÄ(gu©®)ät”║═“2-ęÄ(gu©®)ät”Ą─öĄ(sh©┤)─┐Ż¼┐╔ęį┐┤│÷Ż¼Å─╬─╝■įLå¢traceųą─▄ē“Ą├ĄĮ┤¾┴┐ĻP┬ō(li©ón)ęÄ(gu©®)ätŻ¼┴Ē═ŌŻ¼“2-ęÄ(gu©®)ät”Ą─öĄ(sh©┤)─┐ŽÓ«ö┐╔ė^Ż¼ęčėąĄ─╬─╝■ŅA╚ĪĘĮĘ©║÷┬įĄ¶╬─╝■ų«ķgĄ─3š▀ĻPŽĄŻ¼┤_īŹüGĄ¶┴╦ę╗ą®īÜ┘FĄ─╬─╝■ŅA╚ĪÖCĢ■ĪŻ
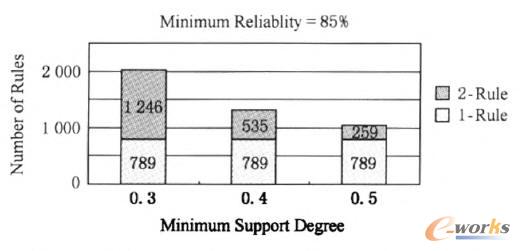
łD5 ╔·│╔Ą─¤o╚▀ėÓĄ─ÅŖĻP┬ō(li©ón)ęÄ(gu©®)ät
Ž┬├µ£yįćūŅąĪ┐╔ą┼Č╚╚ĪųĄī”╦∙╔·│╔Ą─ĻP┬ō(li©ón)ęÄ(gu©®)ätĄ─öĄ(sh©┤)─┐Ą─ė░ĒæŻ¼ūŅąĪų¦│ųČ╚ķōųĄ╣╠Č©×ķ0.5Ż¼īóūŅąĪ┐╔ą┼Č╚ķōųĄÅ─75%Ė─ūāĄĮ90%Ż¼łD6Įo│÷┴╦ūŅąĪ┐╔ą┼Č╚╚ĪųĄ▓╗═¼Ģr╔·│╔Ą─ĻP┬ō(li©ón)ęÄ(gu©®)ätĄ─öĄ(sh©┤)─┐Ż¼┐╔ęį┐┤│÷Ż¼ļSų°ūŅąĪ┐╔ą┼Č╚ķōųĄĄ─į÷╝ėŻ¼╦∙╔·│╔Ą─ĻP┬ō(li©ón)ęÄ(gu©®)ät├„’@£p╔┘Ż¼«öūŅąĪ┐╔ą┼Č╚ķōųĄ╚Ī×ķ90%ĢrŻ¼ĻP┬ō(li©ón)ęÄ(gu©®)ätöĄ(sh©┤)─┐×ķ698Ż¼į┌ūŅąĪ┐╔ą┼Č╚ķōųĄÅ─75%ūā╗»ĄĮ90%Ą─▀^│╠ųąŻ¼ĻP┬ō(li©ón)ęÄ(gu©®)ätöĄ(sh©┤)─┐Č╝▌^┤¾ĪŻ
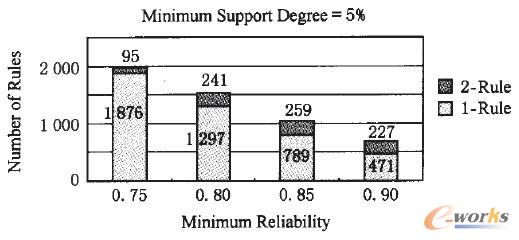
łD6 ūŅąĪ┐╔ą┼Č╚╚ĪųĄī”╔·│╔ĻP┬ō(li©ón)ęÄ(gu©®)ätĄ─ė░Ēæ
3.4 ╦┘┬╩┐žųŲĄ─ą¦╣¹
įuārAutoMigĄ─╦┘┬╩┐žųŲą¦╣¹░³└©╬óė^£yįć║═║Ļė^£yįć2▓┐ĘųŻ¼╩ūŽ╚╩ŪÅ─╬óė^╔Žė^▓ņAutoMigį┌žō▌dūā╗»Ģr╩Ū╚ń║╬┐žųŲöĄ(sh©┤)ō■(j©┤)▀węŲ╦┘┬╩Ą─Ż¼▓źĘ┼▓«┐╦└¹Ą─research traceĄ─═¼ĢrŻ¼į┌Tri-RightŽĄĮy(t©»ng)ā╚(n©©i)▓┐ėøõøžō▌dūā╗»ŪķørŻ¼ęį╝░ŽÓæ¬Ą─öĄ(sh©┤)ō■(j©┤)▀węŲ╦┘┬╩Ż¼īŹ“×ųąŽĄĮy(t©»ng)ģóöĄ(sh©┤)╚ĪųĄ×ķW=100 IOPS.łD7Įo│÷┴╦Ū░┼_I/Ožō▌d├▄╝»│╠Č╚║═öĄ(sh©┤)ō■(j©┤)▀węŲ╦┘┬╩Ą─ī”æ¬ĻPŽĄŻ¼ļSų°žō▌dĄ─▓©äėŻ¼▀węŲ╦┘┬╩ŽÓæ¬ĄžäėæB(t©żi)ūā╗»Ż¼╦┘┬╩ūā╗»Ą─╣š³cČ╝╩Ū╩▄«öŪ░žō▌dĀŅæB(t©żi)Ę┤üĄ─ė░ĒæŻ¼═¼ĢrŻ¼▀węŲ╦┘┬╩▓ó▓╗═Ļ╚½ļSų°žō▌dČČäėČ°ČČäėŻ¼Č°╩ŪĘ┤ė│žō▌dūā╗»Ą─š¹¾w┌ģä▌ĪŻ
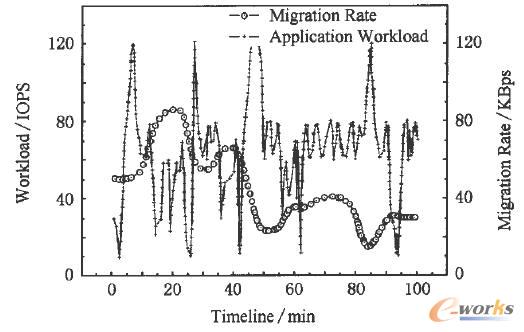
łD7 ▀węŲ╦┘┬╩ļSžō▌dĄ─ūā╗»
║Ļė^£yįć╩Ūī”▒╚į┌═Ļ│╔═¼śėĄ─▀węŲ╚╬äšĢrŻ¼╩╣ė├║═▓╗╩╣ė├AutoMig▀węŲ╦┘┬╩┐žųŲŽ┬Ū░┼_I/OĒææ¬ĢrķgŻ¼īŹ“×ųą▀węŲ20éĆ┤¾ąĪ×ķ512 MBĄ─╬─╝■Ż¼╩╣ė├▓óąą╬─╝■ŽĄĮy(t©»ng)ąį─▄£yįć╣żŠ▀IORüĒ╔·│╔Ū░┼_I/Ožō▌dŻ¼▓ó╩š╝»I/Očė▀tŻ¼├┐┤╬£yįć░³└©ā╔▌å裣h(hu©ón)Ż¼├┐▌å裣h(hu©ón)Č╝░³└©╬─╝■┤“ķ_ĪóūxīæĪóĻPķ]Ą╚▓┘ū„ĪŻ
łD8Įo│÷┴╦ėą¤oAutoMig╦┘┬╩┐žųŲĄ─Ū░┼_I/OĒææ¬Ģrķgī”▒╚Ż¼ŲõųąŻ¼read0Ż¼write0Ęųäe▒Ē╩ŠĄ┌1▌å裣h(hu©ón)ųąĄ─ūxĪóīæšłŪ¾Ą─ŲĮŠ∙Ēææ¬ĢrķgŻ╗readl,writelĘųäe▒Ē╩ŠĄ┌2▌å裣h(hu©ón)ųąĄ─ūxĪóīæšłŪ¾Ą─ŲĮŠ∙Ēææ¬ĢrķgŻ¼ī”▒╚ėą¤oAutoMig╦┘┬╩┐žųŲ2ĘNŪķørŻ║Ą┌1▌å裣h(hu©ón)ųąĄ─īæšłŪ¾Ż¼AutoMig╦┘┬╩┐žųŲĮĄĄ═┴╦Ū░┼_IŻ»OĒææ¬Ģrķg47Ż«84ŻźŻ╗Ą┌1▌å裣h(hu©ón)ųąĄ─ūxšłŪ¾Ż¼AutoMig╦┘┬╩┐žųŲĮĄĄ═┴╦Ū░┼_IŻ»OĒææ¬Ģrķg13Ż«03ŻźĪŻĄ┌2▌å裣h(hu©ón)ųąĄ─īæšłŪ¾ĮĄĄ═┴╦Ū░┼_IŻ»OĒææ¬Ģrķg29Ż«98ŻźŻ╗Ą┌2▌å裣h(hu©ón)ųąĄ─ūxšłŪ¾ĮĄĄ═┴╦Ū░┼_IŻ»OĒææ¬Ģrķg40Ż«47ŻźĪŻ
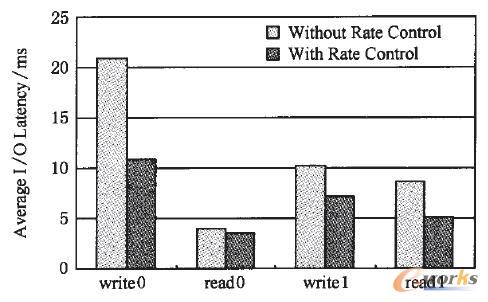
łD8 ėą¤oAutoMig╦┘┬╩┐žųŲĄ─Ū░┼_I/OĒææ¬Ģrķgī”▒╚ĪŻ
4 ĮYšō
▒Š╬─╠ß│÷┴╦Ęų╝ē┤µā”ŽĄĮy(t©»ng)ųąę╗ĘNöĄ(sh©┤)ō■(j©┤)ūįäė▀węŲĘĮĘ©AutoMig.öĄ(sh©┤)ō■(j©┤)äėæB(t©żi)Ęų╝ē▓▀┬įŠC║Ž┐╝æ]┴╦╬─╝■įLå¢Üv╩ĘĪó╬─╝■┤¾ąĪĪóįOéõĄ─┐šķg└¹ė├ŪķørŻ¼į┌┤¾Ę∙ĮĄĄ═öĄ(sh©┤)ō■(j©┤)▀węŲ┴┐Ą─═¼ĢrŻ¼╠ß╣®Ė³Ė▀Ą─I/Oąį─▄Ż¼╩╣ė├öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ągüĒėąą¦ūRäeŽĄĮy(t©»ng)ųąĄ─╬─╝■ĻP┬ō(li©ón)ąįŻ¼ŅA╚Ī▒╗įLå¢╬─╝■Ą─ĻP┬ō(li©ón)╬─╝■┐╔ęįĮĄĄ═ī”▀@ą®╬─╝■Ą─įLå¢čė▀tŻ¼öĄ(sh©┤)ō■(j©┤)▀węŲĄ─╦┘┬╩┐žųŲŻ¼į┌Ū░┼_I/Oąį─▄ė░Ēæ║═öĄ(sh©┤)ō■(j©┤)▀węŲ═Ļ│╔Ų┌Ž▐ų«ķgīżšę║Ž└ĒĄ─ÖÓ║ŌĪŻAutoMigĘĮĘ©ęčė├ė┌Ęų╝ē┤µā”ŽĄĮy(t©»ng)ųąŻ¼īŹ“×ĮY╣¹▒Ē├„AutoMigėąą¦┐sČ╠┴╦Ū░┼_I/OĒææ¬ĢrķgĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äšŅIė“ĪóąąśI(y©©)æ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻPūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.nttd-wave.com.cn/
▒Š╬─ś╦Ņ}Ż║Ęų╝ē┤µā”ŽĄĮy(t©»ng)ųąę╗ĘNöĄ(sh©┤)ō■(j©┤)ūįäė▀węŲĘĮĘ©(Ž┬)
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.nttd-wave.com.cn/html/support/1112156921.html



▀xą═ųąą─")
¾w“×ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")